

大模型AlpacaFarm分析
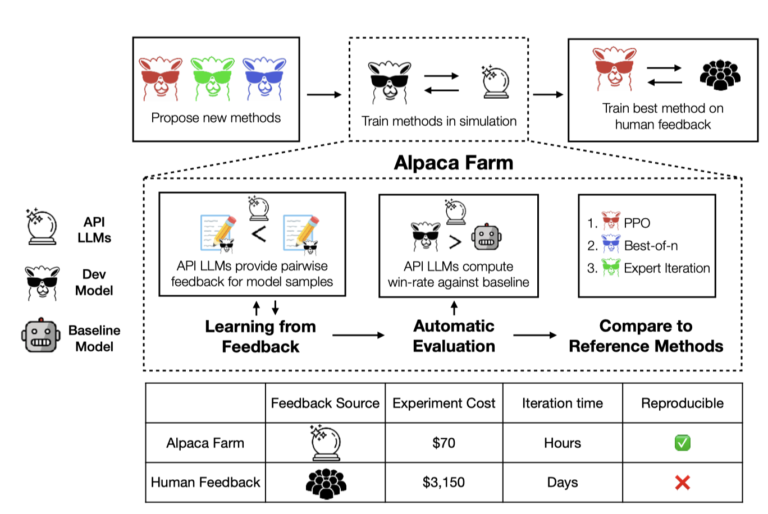
一、摘要 本研究工作介绍了一个名为AlpacaFarm的模拟框架,旨在降低模型从人类反馈中学习方法的成本。作者…
一、摘要 本研究工作介绍了一个名为AlpacaFarm的模拟框架,旨在降低模型从人类反馈中学习方法的成本。作者…
摘要 面对文本评估任务时,人们总是习惯性地想找到一个标准答案作为参考。这源自于一个很自然的思路,和参…

Highlight 论文地址: 表征工程(RepE)是一种借鉴认知神经科学的见解来…

论文:Large Language Models as Optimizers arXiv: Affiliation: …

摘要 研究人员通常只有在深入了解大量文献后才能提出新的想法。学术出版物的数量呈指数级增长,这一事实加…

自回归语言模型 自回归语言模型是一种计算概率的模型,它可以预测一个给定的单词序列中下一个词的概率。它…

对比学习 对比学习是一种通过对比正反两个例子来学习表征的自监督学习方法。对于自监督对比学习,下一个等…

知识图谱可视化Demo Github: 本项…

摘录论文:Sun, Zequn, et al. “A Benchmarking Study of Embedding-based Entity Alignment for Kn…

简介 Dedupe是一个python库,使用机器学习对结构化数据快速执行模糊匹配,重复数据删除和实体对齐。 输入…

简介 从研究人员的主页(HTML)中提取信息,并将信息自动分为三类(您可以添加更多的类)。支持中英文页面。 …
论文摘要 论文为A Survey on Knowledge Graphs: Representation, Acquisition and Applications,发表日期…

引言 本文将采用BERT+BiLSTM+CRF模型进行命名实体识别(Named Entity Recognition 简称NER),即实体识别…

简介 基于知识图谱的问答系统,即KBQA。其中一个简单的实现方法是根据用户输入的自然语言问句,转化为图数…

知识融合包括以下几个部分 本体匹配(ontology matching) 侧重发现模式层等价或相似的类、属性或关系,也…

LDA简介 LDA(Latent Dirichlet Allocation)是一种文档主题生成模型,也称为一个三层贝叶斯概率模型,包…