

留一法交叉验证(LOOCV)
留一法即Leave-One-Out Cross Validation。这种方法比较简单易懂,就是把一个大的数据集分为k个小数据集,其中k-1个作为训练集,剩下的一个作为测试集,然后选择下一个作为测试集,剩下的k-1个作为训练集,以此类推。其主要目的是为了防止过拟合,评估模型的泛化能力。计算时间较长。
适用场景:
数据集少,如果像正常一样划分训练集和验证集进行训练,那么可以用于训练的数据本来就少,还被划分出去一部分,这样可以用来训练的数据就更少了。loocv可以充分的利用数据。
KNN算法简介与MATLAB实现
快速留一法KNN
因为LOOCV需要划分N次,产生N批数据,所以在一轮训练中,要训练出N个模型,这样训练时间就大大增加。为了解决这样的问题,根据留一法的特性,我们可以提前计算出不同样本之间的距离(或者距离的中间值),存储起来。使用LOOCV时直接从索引中取出即可。下面的代码以特征选择为Demo,验证快速KNN留一法。
其中FSKNN1是普通KNN,FSKNN2是快速KNN
主函数main.m
|
1 2 3 4 5 6 7 8 9 10 11 12 |
clc [train_F,train_L,test_F,test_L] = divide_dlbcl(); dim = size(train_F,2); individual = rand(1,dim); global choice choice = 0.5; global knnIndex [knnIndex] = preKNN(individual,train_F); for i = 1:100 [error,fs] = FSKNN1(individual,train_F,train_L); [error2,fs2] = FSKNN2(individual,train_F,train_L); end |
数据集划分divide_dlbcl.m
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
function [train_F,train_L,test_F,test_L] = divide_dlbcl() load DLBCL.mat; dataMat=ins; len=size(dataMat,1); %归一化 maxV = max(dataMat); minV = min(dataMat); range = maxV-minV; newdataMat = (dataMat-repmat(minV,[len,1]))./(repmat(range,[len,1])); Indices = crossvalind('Kfold', length(lab), 10); site = find(Indices==1|Indices==2|Indices==3); test_F = newdataMat(site,:); test_L = lab(site); site2 = find(Indices~=1&Indices~=2&Indices~=3); train_F = newdataMat(site2,:); train_L =lab(site2); end |
简单KNN
FSKNN1.m
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
function [error,fs] = FSKNN1(x,train_F,train_L) global choice inmodel = x>choice;%%%%%设定恰当的阈值选择特征 k=1; train_f=train_F(:,inmodel); train_length = size(train_F,1); flag = logical(ones(train_length,1)); error=0; for j=1:train_length flag(j) = 0; CtrainF = train_f(flag,:); CtrainL = train_L(flag); CtestF = train_f(~flag,:); CtestL = train_L(~flag); classifyresult= KNN1(CtestF,CtrainF,CtrainL,k); if (CtestL~=classifyresult) error=error+1; end flag(j) = 1; end error=error/train_length; fs = sum(inmodel); end |
KNN1.m
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
function relustLabel = KNN1(inx,data,labels,k) %% % inx 为 输入测试数据,data为样本数据,labels为样本标签 k值自定1~3 %% [datarow , datacol] = size(data); diffMat = repmat(inx,[datarow,1]) - data ; distanceMat = sqrt(sum(diffMat.^2,2)); [B , IX] = sort(distanceMat,'ascend'); len = min(k,length(B)); relustLabel = mode(labels(IX(1:len))); end |
快速KNN
preKNN.m
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
function [knnIndex] = preKNN(x,train_F) inmodel = x > 0; train_f=train_F(:,inmodel); train_length = size(train_F,1); flag = logical(ones(train_length,1)); knnIndex = cell(train_length,1); for j=1:train_length flag(j) = 0; CtrainF = train_f(flag,:); CtestF = train_f(~flag,:); [datarow , ~] = size(CtrainF); diffMat = repmat(CtestF,[datarow,1]) - CtrainF ; diffMat = diffMat.^2; knnIndex{j,1} = diffMat; flag(j) = 1; end end |
FSKNN2.m
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
function [error,fs] = FSKNN2(x,train_F,train_L) global choice inmodel = x>choice;%%%%%设定恰当的阈值选择特征 global knnIndex k=1; train_length = size(train_F,1); flag = logical(ones(train_length,1)); error=0; for j=1:train_length flag(j) = 0; CtrainL = train_L(flag); CtestL = train_L(~flag); classifyresult= KNN2(CtrainL,k,knnIndex{j}(:,inmodel)); if(CtestL~=classifyresult) error=error+1; end flag(j) = 1; end error=error/train_length; fs = sum(inmodel); end |
KNN2.m
|
1 2 3 4 5 6 7 8 |
function relustLabel = KNN2(labels,k,diffMat) distanceMat = sqrt(sum(diffMat,2)); [B , IX] = sort(distanceMat,'ascend'); len = min(k,length(B)); relustLabel = mode(labels(IX(1:len))); end |
数据集:https://github.com/xyjigsaw/Dataset 下载DLBCL.mat即可。
结果
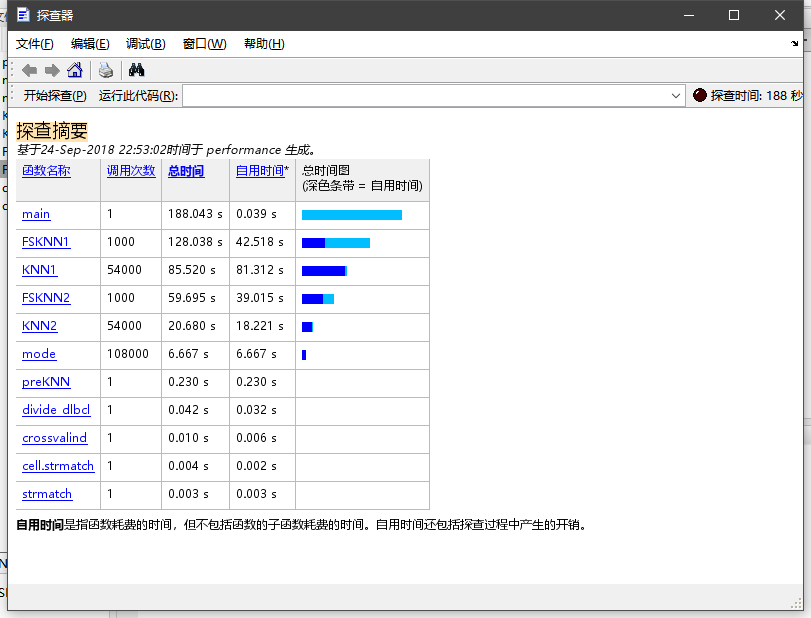
可以看到FSKNN2+preKNN的时间比FSKNN1要少很多。


