


一、摘要
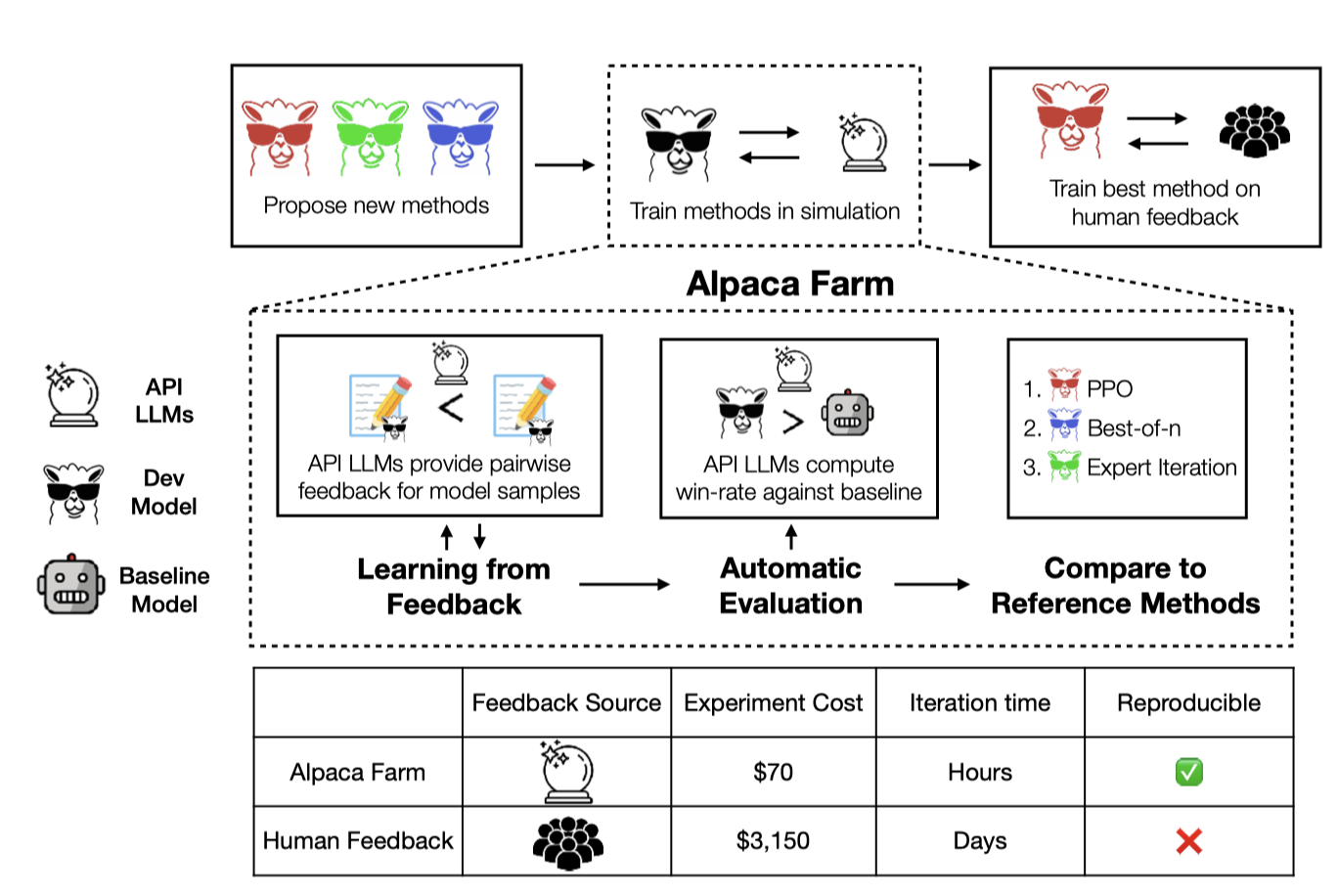
本研究工作介绍了一个名为AlpacaFarm的模拟框架,旨在降低模型从人类反馈中学习方法的成本。作者设计了能够模拟人类反馈的大型语言模型提示,显著降低了数据收集的成本,并与人类评价达成高度一致性。此外,他们提出了一种自动化评估方法,并通过实际人类互动中的指令进行了验证。研究还贡献了多个从成对反馈中学习的参考方法的实现,并在真实人类反馈上训练和评估了十一种模型,证明了在AlpacaFarm中训练的模型的排名与在人类数据上训练的模型的排名相匹配。研究结果表明,使用奖励模型的方法可以显著提高监督微调的性能,且PPO实现在胜率上比Davinci003提高了10%。
二、问题与挑战
解决的问题
大语言模型对齐人类偏好微调的工作流复杂,需要大量的人工反馈来提升模型SFT后的能力。因此,需要一种低成本,可信赖且能够替代现有基于人类反馈的模型训练(RLHF)流程。同时需要完备的评估验证方法来验证其有效性。
面临的挑战
- 偏好数据标注成本高昂
- 缺乏可信的模型自动化评估手段
- 缺乏参考(reference method)方法的实现
三、创新与不足
创新点
- 使用API LLMs模拟人类反馈标注,大幅降低偏好数据标注成本
- 提出了一种自动化评估手段,并通过真实的人类交互指令进行了验证
- 提供了多种参考模型(相对于API LLMs)的实现,如PPO、best-of-n、专家迭代等
有益效果
- 在模拟环境中考察反馈偏好数据对模型性能的影响,能够快速迭代模型开发
- 低资源、低花费场景下,通过类人反馈数据提升模型性能
- 通过模拟反馈训练的模型在真实世界中的性能得到了验证
局限性
- 模拟反馈显然无法完全捕捉人类反馈的多样性、异质性等特征
- 自动评估方法需要不断更新以适应新的指令和反馈类型
- 需要更多的研究来验证模拟器在不同领域和任务中的普适性,例如:
- 通用数据和垂直领域数据的差别
- 模型参数量对性能的影响
- 成对偏好数据偏好角度对性能的影响
- API LLM种类的多样性(文章中只采用了decoder-only的模型作为API)
- 评价角度的公平性
四、垂域任务上的思考与应用
基于专家反馈增强大模型在垂域任务上效果的路径有哪些?
- 强化学习中的人类反馈(RLHF, Reinforcement Learning from Human Feedback):利用人类反馈来指导强化学习的奖励函数。通过对模型输出的评价,赋予正面或负面的奖励来引导模型行为[1]。
优势:有助于模型更好地理解人类的偏好和要求,从而生成更符合任务需求的输出。
技术挑战:
- 奖励函数设计:设计一个合理的奖励函数是非常困难的,因为它需要准确反映人类偏好,同时又不能过于复杂以至于难以优化。
- 反馈质量和一致性:不同的评审者可能会对同一个输出给出不同的评价,导致反馈信号不一致(这种在AlpacaFarm中表现为噪声,这种不一致性是否会促进或阻碍模型性能尚未得到充分验证)。
- 计算和资源开销:RLHF需要大量计算资源进行模型训练,并且需要频繁进行人类评审,成本较高。
- 泛化性与多样性的平衡:论文[1]中,RLHF比SFT对新输入的泛化能力更强,特别是在训练和测试之间的分布偏移变大的情况下。然而,与SFT相比,RLHF在各种测量中显著降低了输出的多样性,因此LLM微调需要考虑泛化能力和输出多样性之间的权衡。
研究方向:
- 开发更智能和灵活的奖励函数设计方法,包括自适应奖励机制和基于多目标优化的奖励函数[2,3,14],以保证其评价的多样性与泛化性能。
- 引入一致性调整和质量控制机制,探索人类反馈的一致性和可靠性对训练的影响[4,5]。
- 探索在有限计算资源下有效进行RLHF训练的方法(例如本文)[6,7]。
- 人类在回路中(HITL, Human in the Loop):在模型训练和评估过程中引入人类干预,迭代地使用人类反馈来纠正和优化模型输出。具体来说,人类可以参与数据标注、实时校正错误输出以及提供进一步的解释和指导[8]。
优势:提高模型在特定领域的准确性和可靠性,人类专家的实时输入有助于快速纠正模型的错误。
实现方式:创建一个交互式系统,允许人类专家在模型生成响应时提供即时反馈和修改,并将这些反馈用作模型的训练数据。
技术挑战:
- 响应时间和效率:人类干预会增加系统的响应时间,在实时应用中,可能会导致延迟和效率降低。
- 可扩展性:随着模型规模和数据量的增加,人工参与的规模也需要相应增加,可能难以持续扩展。
- 人类专家的依赖:对高质量人类专家的依赖可能会成为瓶颈,特别是在高度专业化的垂直领域中,找到合适的专家进行持续反馈可能不容易。
研究方向:
- 人机交互方向,开发半自动化辅助工具,降低人类专家在回路中的干预时间和工作量[9,10]。
- 除此以外,针对专家依赖同RLHF。
- 主动学习(Active Learning):模型会主动选择那些它最不确定或难以预测的样本,并请求人类专家对这些样本进行标注。这样可以最大化地利用人类反馈,提高训练数据的质量和模型的性能[11]。
优势:高效利用人类标注资源,通过聚焦在最难或最模糊的样本上,可以显著提高模型的性能。
实现方式:利用不确定性采样等策略,让模型选出最需要人类反馈的样本,并将这些样本优先提交给人类专家进行标注。
技术挑战:
- 选择策略的复杂性:选择哪些样本需要人类反馈是一个复杂的问题,特别是当样本空间非常大时。选择策略需要平衡不确定性和代表性,以确保选择的样本能最大化地提高模型性能。
- 反馈的及时性:主动学习需要人类迅速地标注选择的样本,如果反馈不及时,可能会延迟模型的更新和提升。
- 样本的不平衡性:在某些情况下,主动学习可能会导致数据集中的某些类别过于稀疏,从而影响模型在这些类别上的表现。
研究方向:
- 研究样本平衡技术,确保在主动学习过程中数据集的多样性分布均衡[12]。
- 主动学习与Human-in-the-loop结合,提高其反馈的时效性[11]。
- 探索在稀疏类别或OOD(out-of-distribution)场景数据增强策略以支持主动学习[13]。
五、参考文献
[1] Kirk, Robert, et al. “Understanding the effects of rlhf on llm generalisation and diversity.” arXiv preprint arXiv:2310.06452 (2023).
[2] Wang, Binghai, et al. “Secrets of rlhf in large language models part ii: Reward modeling.” arXiv preprint arXiv:2401.06080 (2024).
[3] Yuan, Weizhe, et al. “Self-rewarding language models.” arXiv preprint arXiv:2401.10020 (2024).
[4] Li, Aaron J., Satyapriya Krishna, and Himabindu Lakkaraju. “More RLHF, More Trust? On The Impact of Human Preference Alignment On Language Model Trustworthiness.” arXiv preprint arXiv:2404.18870 (2024).
[5] Wang, Shiqi, et al. “Offline RLHF Methods Need More Accurate Supervision Signals.” arXiv preprint arXiv:2408.09385 (2024).
[6] Wang, Peiyi, et al. “Large language models are not fair evaluators.” arXiv preprint arXiv:2305.17926 (2023).
[7] Sun, Zhiqing, et al. “Salmon: Self-alignment with principle-following reward models.” arXiv preprint arXiv:2310.05910 (2023).
[8] Mosqueira-Rey, Eduardo, et al. “Human-in-the-loop machine learning: a state of the art.” Artificial Intelligence Review 56.4 (2023): 3005-3054.
[9] Wang, Xinbing, et al. “AceMap: Knowledge Discovery through Academic Graph.” arXiv preprint arXiv:2403.02576 (2024).
[10] Amirizaniani, Maryam, et al. “Developing a framework for auditing large language models using human-in-the-loop.” arXiv preprint arXiv:2402.09346 (2024).
[11] Kholodna, Nataliia, et al. “LLMs in the loop: leveraging large language model annotations for active learning in low-resource languages.” Joint European Conference on Machine Learning and Knowledge Discovery in Databases. Cham: Springer Nature Switzerland, 2024.
[12] Bayer, Markus, and Christian Reuter. “ActiveLLM: Large Language Model-based Active Learning for Textual Few-Shot Scenarios.” arXiv preprint arXiv:2405.10808 (2024).
[13] Gebreegziabher, Simret Araya, et al. “Leveraging Variation Theory in Counterfactual Data Augmentation for Optimized Active Learning.” arXiv preprint arXiv:2408.03819 (2024).
[14] Bansal, Hritik, John Dang, and Aditya Grover. “Peering through preferences: Unraveling feedback acquisition for aligning large language models.” arXiv preprint arXiv:2308.15812 (2023).



